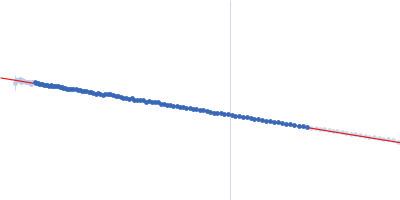
| MWI(0) | 64 | kDa |
| MWexpected | 69 | kDa |
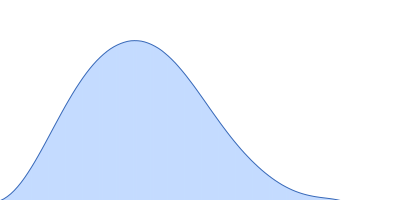
| VPorod | 97 | nm3 |
|
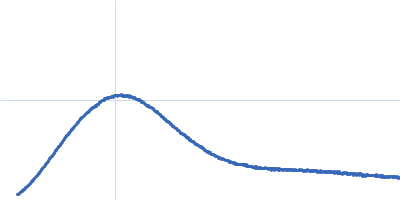
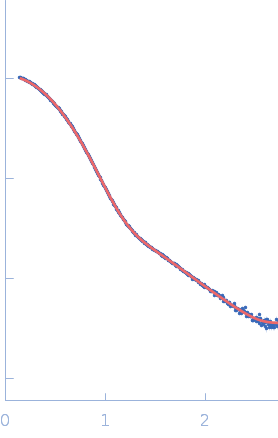
log I(s)
5.93×101
5.93×100
5.93×10-1
5.93×10-2
|
 s, nm-1
s, nm-1
|
|
|
|

|
|

|
|
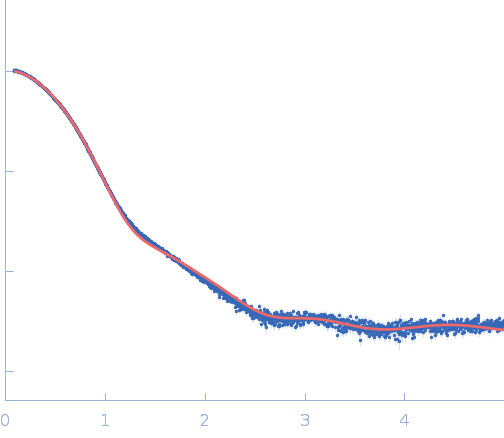
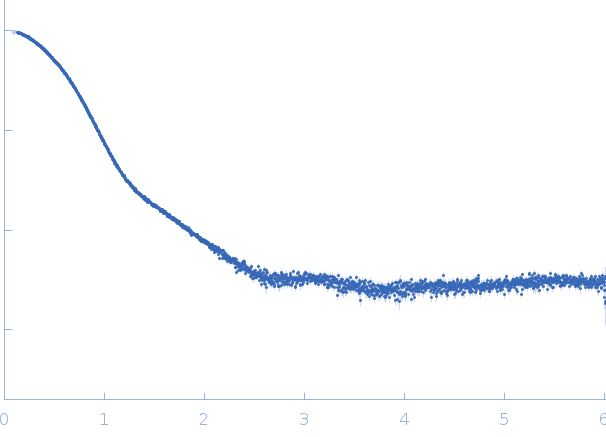
Synchrotron SAXS
data from solutions of
Bovine serum albumin in HEPES
in
50 mM HEPES 50 mM KCl, pH 7.5
were collected
on the
EMBL X33 beam line
at the DORIS III, DESY storage ring
(Hamburg, Germany)
using a Pilatus 1M-W detector
at a sample-detector distance of 2.7 m and
at a wavelength of λ = 0.15 nm
(I(s) vs s, where s = 4πsinθ/λ, and 2θ is the scattering angle).
One solute concentration of 25.64 mg/ml was measured
at 10°C.
Eight successive
15 second frames were collected.
The data were normalized to the intensity of the transmitted beam and radially averaged; the scattering of the solvent-blank was subtracted.
Tags:
X33
|
|
|||||||||||||||||||||||||||